on
SELinux Policy Module Primer
Its been a while since my last post, I apologize but I have a good reason I promise ![]() . I’ve been busy working on a series of patches to make the SELinux policy compiler and libraries much more stable and robust and to make optional blocks in the base policy work correctly. While the libraries and compiler are fresh on my mind I thought I’d go ahead and write an article on how the SELinux policy modules work.
. I’ve been busy working on a series of patches to make the SELinux policy compiler and libraries much more stable and robust and to make optional blocks in the base policy work correctly. While the libraries and compiler are fresh on my mind I thought I’d go ahead and write an article on how the SELinux policy modules work.
Once upon a time the SELinux policy compiler was a simple creature. It was self-contained and merely translated source rules into the binary policy in a fairly 1:1 fashion. It became apparent that this kind of policy was difficult to use on complicated systems like Linux and conveniences like attributes were added. The compiler was still simple but had the potential of converting one source rule into many rules in the binary. This is about the time I started working on SELinux, back in early 2003. This worked out fine for a while, as long as users had the policy source on their machines in order to do any kind of customizations at all to the policy (including fairly simple things like adding users). Clearly Hardened Gentoo was fine with this since we compile everything from scratch anyway. Red Hat, however, didn’t share our sentiment. Soon after Red Hat did their initial integration work in 2004 the need to make modifications to the policy on production machines became clear. The initial extent was small, only users could be added to the policy and Booleans could be made persistent (lasting across reboots). This required much of the policy infrastructure to be factored out into a library called libsepol. The compiler now links statically against libsepol to build up the policydb structure (the structure that the entire policy is stored in) and other applications can link against libsepol to do operations on the binary policy as well. Originally init and load_policy were modified to read a file with users and a file with Boolean settings and apply them to the policy before loading it into the kernel. The customizations specified in these files never were written to the policy on the disk.
While this was a useful progression and necessary for Red Hat’s integration there were some concerns about mutating the policy in memory before loading it (and never having a copy of the mutated policy on disk to analyze). The initial customizations wouldn’t have affected analysis much but there were some concerns of a slippery slope and it couldn’t be long before people would want to add rules to the policy without having the source around.
At the same time all of this was going on I had started working at Tresys and one of my first projects was to implement loadable policy modules. We went through several different designs and finally ended up with what you see today, for better or worse. The current module implementation has some limitations, some that we plan to address such as interfaces being part of the language, but are now in pretty good working order for the upcoming FC6 and RHEL5 releases. Now that modular systems are going to be deployed in released systems I hope to educate people about what they are and how they work. So, now that all the history is out of the way lets get dirty.
All policies are stored in a struct called policydb which is defined in libsepol/include/sepol/policydb/policydb.h. A simplified version of the struct looks like this:
struct policydb {
policy_type; /* specifies whether this is a base, module or kernel policy */
symtabs; /* hashtables of symbols including types, classes, roles, etc */
indexes; /* various indexes used during processing and compiling */
/* --- Stuff only in modules (base or module) -- */
name; /* name of module (only used for modules) */
version; /* version of module (only for modules) */
scope_tables; /* tables that tell the scope of each symbol, what optionals
* they were declared in or required in */
avrules; /* linked list of rule blocks, one for the global scope of a
* module and one for each optional block in the module. Avrule
* blocks contain everything that can be in an optional such as
* symbol declarations, allow rules, role allows, and conditionals
*/
/* -- Stuff only in kernel policy -- */
avtab; /* hash table of rules, keyed on source type value, target type
* value,class value and rule type (allow, dontaudit, auditallow)
*/
role_trans; /* role transition rules */
role_allow; /* role allow rules */
/* -- Stuff only in kernel and base -- */
ocontexts; /* other contexts like ports, nodes, initial sids, etc */
genfs; /* genfs contexts like /proc */
};
So now that the policy format is as clear as mud we can go into some of the specifics. You’ll note that, although the module, base and kernel formats are slightly different, they all share the same struct. This was done for simplicity sake since there is significant overlap and code reproduction for multiple structs would have been much harder to maintain.The most notable difference between the modular/base and kernel formats is that they serve a different purpose. The kernel format has an efficient way to look up access vectors (allowed permissions) for any given source, target, class: hash the values and do an O(1) hashtable lookup (for now we’ll ignore the version 20 changes). The module format, on the other hand, can’t easily look up an access vector. The module format, however, stores something that is much more representative of the original rule that was in the source code (we’ll call this the symbolic representation from now on). For example, consider a rule like this in the source:
allow portage_t { file_type -shadow_t }:file { read getattr lock ioctl };
This rule says that the domain type portage_t can read, getattr, lock and ioctl all file objects in the file_type attribute (which is all of them) except shadow_t. In the kernel format this rule would expand to a rule for each type in file_type (which is often over 1000) except shadow_t. The purpose for this type of expansion is so that when the kernel security server receives a request for portage_t to, say, etc_t with the file object class and the permission read it can simply hash the value of portage_t , etc_t, file and get the corresponding set of allowed permissions. This is ideal from the enforcement point of view but we needed something different from rules.
The modules needed to maintain what the source says, specifically the { file_type -shadow_t } part. This is because from within a module the final meaning of file_type would not be known. No single module has a full picture of the entire policy and therefore no module can determine what the expanded set of rules for this single source rule would be. Further more complex things like subtracting an attribute require us to carefully preserve what the source says, included deprecated syntaxes like * and ~ in the type fields.
So, in the modular format a rule is stored individually (and potentially redundantly) in a struct that looks like this:
struct avrule {
rule_type; /* the kind of rule, allow, dontaudit, neverallow, etc */
type_set source; /* set of source types */
type_set target; /* set of target types */
class_perm_list; /* linked list of classes and permissions */
}
struct type_set {
types; /* ebitmap of all types specified */
negset; /* ebitmap of all types negated */
flags; /* whether * or ~ were used */
}
Using these structs we can specify the above rule fairly easily. The source type_set would have only portage_t in the types ebitmap and the target would have file_type in the types and shadow_t in the negset. The class_perm_list preserves all the classes and * and ~ for permissions.
The main difference between a kernel policy and a base module is the rules, as shown above, the other fields are mostly the same. A policy module is a subset of a base module in that it cannot have any kind of labeling (such as filesystem or networking). The policy modules also do not support MLS yet so all MLS related stuff (level and category definitions, range transitions and users with mls levels) must be in the base.
Hopefully at this point you’ll have a good idea what modules are for and how they are different from the policy loaded into the kernel so I’ll continue by explaining how it is that modules work their way to becoming a policy that can be loaded into the kernel.
First a graphical representation of the linking, the modules are copied into the base policy:
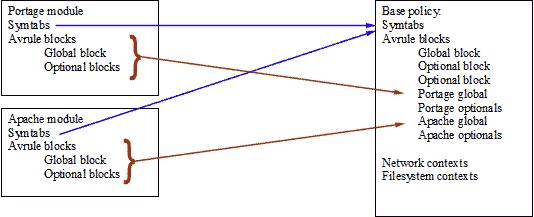
I’m not sure how obvious this image is but hopefully it shows the portage symbols (eg., portage types) being copied into the base policy symbol tables (and the type values change since the base will probably have types with the same values as the portage module so the maps are set up to know what value a type had in its module and what the corresponding value is in base). Next the avrule blocks get copied into the base. They are linked into the list of avrule blocks already there. The same thing happens with the apache module. This new base (or linked copy) is then a superset of base and all the modules. All the symbols from the modules have new (unique) values in base so when the rules are copied the new mapped values must be used. There is quite a bit of technical detail about the copying that I’ll just skim over here, if anyone is interested let me know and I can write something more in depth later.
After all the avrule blocks have been copied to the base the dependency checker is run. Each module declares its symbol dependencies explicitly. This means that if the portage module needs to use file_type and shadow_t (as in the earlier rule) those types and attributes must be explicitly requested in require { } blocks. Note: in reference policy require blocks are not seen in .te files since the interfaces that use symbols always request them before using them. Optional blocks also have require { } blocks to determine whether that optional block will be enabled.
The dependency algorithm enables all optional blocks and then loops through them determining if the symbols required by those blocks are satisfied. When the requirements are found to be unsatisfied the block in question is disabled and the loop continues. If a global block (which is the unconditional part of each module) is ever disabled the dependency checker will immediately bail and tell the user that the requirements for that module were not met. The global block in the base module is self contained and may not have any require { } blocks.
Once we have decided which blocks are enabled and marked them thusly we are done with the link phase and are ready to send the linked policy to the expander. The expander is fairly simple in theory but in practice a lot of stuff has to be done to ensure the policy is correctly created. When the expander is called two policydb’s are passed in, the linked copy and a brand new empty copy. The expansion is done into a fresh policydb for simplicity so that no cruft is left in from the linked copy which has much more information (such as every symbol, whether it turns out to be disabled or not).
The expander starts by going through each symbol table and copying over only the symbols that are enabled. The symbols are mapped to new values so that there are no values left unused in the resulting policy which would cause the policy to be bigger with no advantage whatsoever. Once all the enabled symbols are copied over the avrule blocks are looped through, first the rules are expanded from the symbolic representation into the avtab (a hashtable that holds all the rules, keyed on the source type, target type, class value and rule type). The datum of that hashtable is simply a 32 bit bitmap of the allowed permissions. The avrule blocks also hold “additive” symbols, which are symbols that have a list of something in the datum. The additive symbols are attributes (which have a list of types), roles (which have a list of types, and users (which have a list of roles). If the avrule block is enabled the additive symbol datums are OR’d into the main symbol table of the expanded copy. For example, if an avrule block has a line like:
typeattribute portage_t file_type;
then portage_t is added to the datum of file_type in the expanded copy. Once all the avrule blocks have been evaluated all the rules and the additive symbols are complete. The expanded copy is now a valid policy loadable by the kernel. One last thing has to be done, the linked copy holds neverallows in the symbolic form. Tthese neverallows are copied into the expanded copy in the same form (and later discarded) and are used to determine if the final expanded policy violates any of these rules. If no neverallow assertions have been violated the hierarchy checker is run. The hierarchy checker is a validation stage introduced for the policy server which enforces the idea that a hierarchal type (like portage_t.merge, the portage type used for merging files onto the filesystem) cannot have more permissions than the parent type (portage_t in this example). I can go into the details and purpose of hierarchal namespaces in another article.
After these post-checks are done the policy is ready to be written to disk and loaded into the kernel. The mechanism described here is what happens in libsepol from modules to a kernel policy, in practice libsemanage, the new library that manages policies on FC5 and RHEL5 systems handle all of this and also does some other policy manipulations. I’ll can also talk about these another time.
So that is how SELinux policy modules work in a nutshell. Hope this helps anyone interested in this particular subject.